Build a FAIR Knowledge Graph
Vincent Emonet
Data Science engineer at IDSThis tutorial will help you generate a knowledge graph from some structured datasets such as CSV, JSON and XML. We will use Semantic Web technologies to build our knowledge graph. If you are not familiar with Semantic Web technologies, we provide you with some basic concepts and technologies about Semantic Web based Knowledge Graphs.
Knowledge Graph 101#
Back in 1999 the W3C laid down the Semantic Web principles, an utopia where all data published on the web would be published in a standard manner, interconnected, and shared. To live the dream, a standard way to describe and link knowledge graphs has been defined: the Resource Description Framework (RDF).
There are multiple definitions to a knowledge graph, most of them come down to being nodes connected by edges. The Semantic Web/RDF stack provides standards to build interconnected knowledge graphs at the web scale. This article will focus on using those standards.
Multiple concepts have been defined since then, to provide a structured and coherent framework for knowledge representations (this goes further than just building graphs and networks!). Here is a quick glossary of some of concepts that will be used in this tutorial 📖
- URI, aka. URL: they are used to identify concepts, properties and entities. e.g. https:///w3id.org/mykg/MyConcept
- RDF: the standard knowledge graph format to describe nodes and edges as triples (subject, predicate, object). e.g. "MyConcept is a Restaurant"
- Ontologies, aka. vocabularies: the data models for knowledge graphs, they describe their classes and properties. e.g. the class https://schema.org/Restaurant in Schema.org vocabulary
- SPARQL: the language to query RDF Knowledge Graphs stored in triplestores (database for RDF) through a SPARQL endpoint
- RML: the RDF Mapping Language is a language, based on the R2RML W3C recommendation, to map any structured data (CSV, JSON, XML, SQL) to RDF. Mappings themselves are expressed in RDF.
- YARRRML: a simplification of RML to define mappings in the human-readable YAML format, easier to write than the RML RDF.
Let's get started#
This short tutorial aims to build a RDF Knowledge Graph about restaurants and cuisines from 2 tabular files samples generated from a dataset found on data.world, using mappings expressed in the popular human-readable YAML format.
We will use tools, data models and formats based on recommendations from the World Wide Web Consortium (W3C) to build a knowledge graph as "FAIR" as possible (Findable, Accessible, Interoperable, Reusable).
This guide consists of the following steps:
- Search for relevant ontologies/vocabularies to describe your knowledge graph content.
- Properly deal with using multiple ontologies, and describing missing properties.
- Map CSV files to a coherent RDF knowledge graph, and generate the RDF knowledge graph.
Choose a data model#
We first need to define a data model for our Knowledge Graph. A knowledge graph data model consists of concepts and properties, defined in an ontology, or vocabulary.
Choosing the right concepts and properties for your Knowledge Graph from existing and recognized ontologies is the most important part of the process to publish data in a standard and reusable manner. If your knowledge graph uses the same ontology (concepts and properties) as other knowledge graphs, it will be easier to connect your graph to existing data published in those knowledge graphs.
Using existing ontologies connects your graph to existing data published using the same ontologies. Using your own URIs for properties and entities types makes your RDF Knowledge Graph isolated, and completely miss the point of building a knowledge graph. Whereas if you use your own URIs for properties and entities types, your RDF Knowledge Graph might be isolated, and not linked to other data resources.
Let's take a look at the 2 files we want to integrate in our knowledge graph.
dataworld-restaurants.csvhas information about restaurants, and which cuisine they serve:
| Restaurant ID | Restaurant Name | City | country name | Address | Locality | Locality Verbose | Longitude | Latitude | Cuisines | Average Cost for two | Currency | Has Table booking | Has Online delivery | Is delivering now | Switch to order menu | Price range | Aggregate rating | Rating color | Rating text | Votes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 53 | Amber | New Delhi | India | N-19, Connaught Place, New Delhi | Connaught Place | Connaught Place, New Delhi | 77.220891 | 28.630197 | indian | 1800 | Indian Rupees(Rs.) | Yes | Yes | No | No | 3 | 2.6 | Orange | Average | 152 |
dataworld-cuisines.csvis slightly different from the original on Data.world as I ran a quick preprocessing step to concatenate the diets columns and make the mapping easier:
| cuisines | diets |
|---|---|
| Chinese | vegetarian|low_lactose_diet |
| indian | halal|low_lactose_diet|vegetarian |
In this case we followed those steps to define our Knowledge Graph concepts and properties:
Schema.org is a good vocabulary built by Google which covers a large amount of concepts and properties. It is the standard vocabulary used by prominent Search Engines, such as Google search, to understand metadata. It covers most of the entities and properties we want to create for the columns of the
dataworld-restaurants.csvfile (such asschema:priceRangeorschema:priceRange, see the mappings code to discover the complete list of properties used)The "Cuisine" concept does not exist in Schema.org: the
schema:cuisinepoints to a text, but in this case we want to create a new entity for cuisines, to better connect them. So we will search "food ontology cuisine" in Google, to find a more specific ontology about food. We find thefo:Cuisineconcept from the Food Ontology published by the BBC.Unfortunately there are no properties to express that a cuisine is recommended for a specific diet,
schema:suitableForDietandfo:dietscan be use only on recipes entities, so we will need to create a new property to express it,mykg:recommendedForDiet
Another interesting ontology would have been FoodON, which is really detailed and well connected to other ontologies, but in our simple use-case the Cuisine concept from the BBC Food Ontology is good enough.
Note that multiple ontologies repositories can be also consulted to search for relevant concepts and ontologies:
- Linked Open Vocabularies (LOV)
- BioPortal repository for biomedical ontologies
- EBI Ontology Lookup Service, also for biomedical ontologies
- AgroPortal repository for agronomy ontologies
Build the knowledge graph#
We will use the Matey web editor to execute YARRRML mappings to convert 2 small CSV files. The operation can be scaled up to larger files by using the RMLMapper Java implementation, or the RMLStreamer for really large files.
Create 2 new datasources for the
dataworld-restaurants.csvanddataworld-cuisines.csvfiles. Click on the Input: tab on the left of the Matey web UI to create new datasources.
dataworld-restaurants.csv:
dataworld-cuisines.csv:
- Copy/paste those YARRRML mappings in the input: YARRRML box in the middle of the Matey web UI, we added comments to explain the different part of the mappings.
Note that we use our own mykg: namespace for the Knowledge Graph entities URIs (the restaurants and cuisines entities generated). But we use already existing ontology terms for the properties and entity classes.
We used the free w3id.org persistent ID system to define our mykg: URI. We did not created a new entry in w3id.org since this is an example, but this can be easily done with a simple pull request to their GitHub repository.
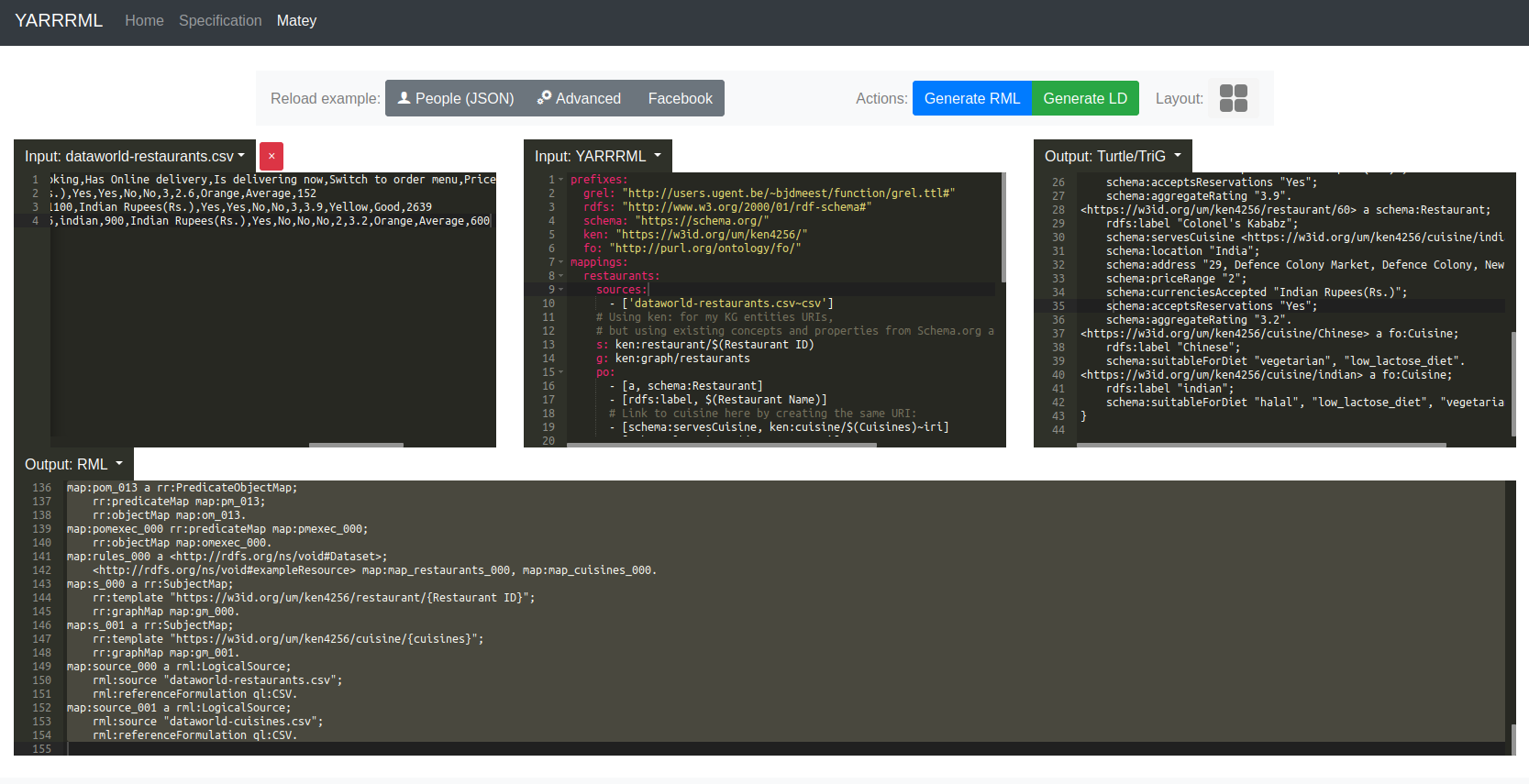
- Click on Generate RML, then Generate LD buttons. The conversion should take around 10s.
Here is a screenshot of what you should see after converting the data, the RDF Knowledge Graph has been generated in the Output: Turtle/TriG panel on the right.
- To be more semantically accurate, we will need to add a few triples to describe some properties we use that are not described in Schema.org or the Food Ontology.
We need to indicate that entities with the type
schema:Restaurantare also considered asfo:Restaurant. This improves the knowledge graph semantics, since thefo:cuisineis not defined as a property ofschema:Restaurantin the Schema.org vocabulary. We can use the standardowl:equivalentClassproperty to indicate the 2 ontology classes are equivalent with a triple:We also need to define the
mykg:recommendedForDietproperty used withfo:Cuisineentities, we will define it as a OWL property, with basic metadata about the property domain and range.
The missing statements can be easily defined as RDF in the Turtle format, and loaded with the RDF generated for your knowledge graph:
Publish the RDF#
To be able to query your RDF Knowledge Graph, you will need to host it in a triplestore (a database for RDF data). There are a lot of different triplestore solutions out there, most of them expose a SPARQL endpoint which enable anyone to query your RDF Knowledge Graph using the SPARQL query language.
- Host your own triplestore: if you have access to a server, and are savvy enough, you can easily deploy a triplestore for free such as OpenLink Virtuoso, Blazegraph, StarDog, or Ontotext GraphDB, and load your RDF Knowledge graph in it.
- Another solution, for small pieces of RDF data, would be to publish your RDF as Nanopublications which is a decentralized network of triplestores using encrypted keys and ORCID accounts to authenticate publishers. This can be done easily with the nanopub-java library, or the nanopub Python package.
- You can also pay for a cloud service provider to publish and expose RDF Knowledge Graphs, such as Amazon Neptune or Dydra
Next steps 🔮#
Publish the code used to generate the knowledge graph in a public Git repository (e.g. GitHub or GitLab). Provide all relevant information to reproduce the process in the
README.mdfile.You can add SPARQL queries examples ✨️ to help people who want to query your knowledge graph. Ideally store them in
.rqfiles in a GitHub repository to automatically deploy OpenAPIs with a Swagger UI to query your knowledge graph with.You can also create SHACL or ShEx scheme for your knowledge graph, this will allow you to validate the data added to your knowledge graph to make sure it meets your requirements. Additionally, this provides a precise human and machine readable description of the content of your knowledge graph, and the restrictions it complies with.
Scale up to transform larger files by using the RMLMapper Java implementation, or use the RMLStreamer to stream large files without relying on memory limitations.
Create new RML functions to handle more complex use-cases, such as performing replace in strings, or generating URI identifiers from string.
Use the w3id.org to define your URIs, then head to the w3id.org GitHub repository to define the redirection to resolve your knowledge graph URI in a
.htaccessfile. This can be easily changed later with a simple pull request if the data location changes. This system insure that your knowledge graph always use the same w3id.org URIs, even if the location and resolution system change.
Thanks to 🤝
- The IDLab team at Ghent University for leading the definition of the RML and YARRRML specifications, developing the RML mapper, and deploying the Matey web editor.
- Remzi Çelebi for his help finding the data, and building the knowledge graph.
- The people all other the world who work to define and improve knowledge description standards, usually through the W3C.
Comments are welcome 💬
- Propose improvements to this process
- Point to interesting data sources that could be interesting for another article about building FAIR Knowledge Graph!
- Ask for specific steps that could be more detailed in another article
Create an issue on GitHub to start the discussion 💬